Aprenda como instalar automaticamente seu ambiente de desenvolvimento usando SCD4J
[Resumo]
Este artigo é útil para mostrar ao leitor que a automação de ambientes de infraestrutura está deixando ser um diferencial para se tornar uma necessidade dentro das empresas que desenvolvem software. Além disto, também é apresentada uma ferramenta, chamada SCD4J, que possui um propósito específico para a instalação e configuração de ambientes Java a qual é capaz de simplificar esta automatização em empresas de pequeno e médio porte que optaram por entrar no mundo de entregas contínuas.
Introdução
Após o boom do Continuous Delivery, que aconteceu em meados de 2010, muito tem se falado sobre a importância da automatização de builds, das revisões de código, dos testes (unit, integration, acceptance, performance, etc) e das instalações e configurações de ambientes de TI. O objetivo principal por trás disto tudo é que estas automatizações ajudam a antecipar problemas e a criar sistemas mais confiáveis e de alta qualidade, uma vez que, a cada alteração realizada no código-fonte, uma série de verificações são aplicadas sem a necessidade de qualquer intervenção humana. Porém, na prática, o que vemos sendo utilizado pela indústria de software são apenas as estratégias que envolvem os times de desenvolvimento isoladamente, isto é, deixando de lado uma parte muito importante do processo que é a automatização dos ambientes, o que, em geral, fica a cargo da equipe de infraestrutura.
É importante ressaltar que de nada adianta ter um super time de desenvolvimento que cria funcionalidades magníficas para os ambientes de testes. Isto é, se o time não conhece a fundo o ambiente onde o sistema definitivo será instalado, existe uma possibilidade muito grande de todo este trabalho ir por água abaixo quando a passagem para produção acontecer. Além disto, a experiência nos mostra que os problemas que acontecem durante esta passagem crescem exponencialmente ao tamanho do time e ao intervalo de tempo entre releases.
O motivo por trás destas afirmações é que, em geral, cada desenvolvedor possui uma máquina instalada e configurada diferentemente. Além disto, os ambientes de testes, de homologação e de produção são, comumente, mantidos por pessoas/times diferentes o que acarreta em estruturas e configurações não padronizadas. Como este modelo é muito comum nas empresas que desenvolvem software, também é muito comum ouvir comentários do tipo: “na minha máquina funcionava”, “eu testei no ambiente de testes”, “o time de infraestrutura que não consegue seguir os passos do documento”, e assim vai.
Box 1. O problema é generalizado
Qualquer semelhança não é mera coincidência. Isto é, na verdade, um problema generalizado que a indústria de software está vivenciando atualmente.
A resposta para este tipo de problema inicialmente parece ser bastante simples: basta definir um conjunto de padrões e doutrinar as equipes para que estes padrões sejam seguidos. Porém, na prática, a doutrina e a criação de documentos de configuração (que, além de se serem longos e propícios a erros, rapidamente ficam desatualizados) não são suficientes para garantir a igualdade entre ambientes, uma vez que, a qualquer momento, um indivíduo pode, intencionalmente ou não, modificar seu ambiente sem que os outros integrantes do time fiquem sabendo.
Em resumo, a falta de padrões entre os ambientes e as configurações manuais são responsáveis por muitos dos problemas que as fábricas de software costumam vivenciar. A boa notícia é que já existem soluções consolidadas no mercado para ambos estes problemas. Estas soluções são ferramentas de automatização de ambientes de infraestrutura. Dentre as mais conhecidas podemos destacar Puppet e Chef. Porém, apesar de serem excelentes opções, estas ferramentas são soluções generalistas que acabam gerando complexidade desnecessária para sysadmins e uma curva de aprendizado muito grande para desenvolvedores Java. Infelizmente, estas dificuldades fazem com que pequenas e médias empresas acabem deixando de lado este tipo automatização.
Com o objetivo de atender este nicho carente em automatização surgiu, recentemente, uma ferramenta chamada Simple Continuous Delivery for Java (SCD4J). Diferentemente das citadas anteriormente, esta ferramenta nasceu com um propósito específico para instalação e configuração de ambientes Java. Isto é, apesar de ela ser capaz de realizar a maioria das tarefas que as demais realizam, o alvo principal são empresas de pequeno e médio porte que apostam no desenvolvimento de soluções sobre a plataforma Java e na entrega contínua de software. Desta forma, sysadmins e desenvolvedores podem colaborar para construir automaticamente ambientes mais simples e padronizados. Considerando, é claro, deste a máquina do desenvolvedor até o cluster em produção.
Porque SCD4J?
Como foi mencionado anteriormente, SCD4J é uma ferramenta de automação para instalar e configurar a infraestrutura de sistemas que rodam sobre a plataforma Java. Com apenas um comando é possível instalar clusters e aplicações em qualquer ambiente do ciclo de desenvolvimento do software. Vale destacar que esta ferramenta não é apenas outra alternativa para Puppet e Chef. Ela é, na verdade, uma solução bem mais simples uma vez que foca em um nicho específico.
As principais vantagens de se utilizar SCD4J sobre as concorrentes são:
- Desenhada com um propósito bem específico;
- Isto é, foco em pequenas e médias empresas que optaram por utilizar tecnologias Java e entregas contínuas.
- Praticamente extingue a necessidade de pré configuração dos ambientes;
- Não necessita instalar e configurar servidores coordenadores;
- Não necessita instalar e configurar agentes nos clientes.
- Modelo arquitetural simples e efetivo
- Utiliza o conceito de ganchos (em inglês, hooks) para implementar as lógicas da automação.
- Pequena curva de aprendizado para desenvolvedores Java e Groovy
- A codificação dos ganchos (hooks) é realizada em Groovy.
- Integração direta com repositórios de binários comumente utilizados no mundo Java
- Por exemplo: Artifactory, Nexus, MavenCentral, JCentral, etc.
- Construída sobre soluções modernas e bem conhecidas no mundo Java
- Por exemplo: Java 8, Gradle, Velocity, Mustache, etc.
- Desenvolvedores conseguem rapidamente entrar no mundo de DevOps
- Uma vez que a linguagem e as ferramentas já são conhecidas, basta aprender os conceitos básicos do framework.
Box 2. DevOps
Segundo Wikpedia, DevOps é uma metodologia de desenvolvimento de software que explora a comunicação, colaboração e integração entre desenvolvedores de software e profissionais de TI (Tecnologia da Informação). DevOps é a reação à interdependência entre desenvolvimento de software e operações de TI.
Desenhando os ambientes
Antes de sair automatizando a criação dos ambientes é necessário entender qual é o modelo utilizado no desenvolvimento do software em questão. Além disto, precisamos deixar bem claro para os stakeholders que todos os ambientes devem ser o mais parecidos possível a fim de antecipar problemas e evitar surpresas em produção. Muitas vezes isto implica em mudanças na infraestrutura ou mesmo no processo de desenvolvimento.
Para fins de exemplo, iremos utilizar um modelo simples mas bastante comum no desenvolvimento ágil de software com entregas contínuas. Por motivos de tamanho e escopo, não iremos abortar todos os detalhes. Contudo, iremos exemplificar como é possível fazer tal automatização em uma visão um pouco mais macro. Para mais detalhes, sugerimos que o código-fonte do exemplo, que se encontra no final deste artigo, seja estudado.

Figura 1. Definindo os ambientes
Como é possível verificar na Figura 1, possuímos três ambientes que queremos automatizar a instalação do servidor de aplicações Wildfly. Notem que o desenvolvedor trabalha em um desktop Windows que irá rodar uma única instância do servidor. Em contra partida, a partir do ambiente de testes já possuímos um cluster com, pelo menos, dois nodos. O objetivo de se ter um cluster nesta segunda etapa é que o time de testes precisa validar o sistema em um ambiente o mais próximo possível do final. Por fim, temos o nosso ambiente de produção que nada mais é do que um cluster mais “parrudo” do que o de testes.
Mãos na massa
Após definir os ambientes que queremos automatizar, temos que codificar a instalação. Como discutimos anteriormente, iremos utilizar a ferramenta SCD4J para realizar esta tarefa. A Figura 2 abaixo mostra a estrutura básica de um projeto nesta ferramenta:
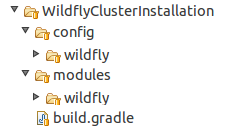
Figura 2. Estrutura do Projeto SCD4J
Como podemos perceber, um projeto de SCD4J é composto de um arquivo build.gradle, que deve ser executado para iniciar a instalação, um diretório modules, que é onde colocamos o código-fonte da automatização, e um diretório config, que deve conter as configurações que são diferenciadas entre os ambiente. Vamos então começar a analisar o arquivo build.gradle.
Listagem 1. Arquivo build.gradle - plugin e dependências
1. plugins {
2. id "com.datamaio.scd4j" version "0.7.5"
3. }
4.
5. dependencies {
6. scd4j url('http://download.jboss.org/wildfly/8.2.0.Final/wildfly-8.2.0.Final.zip'),
7. files('dependencies/cluster-checker.war')
8. }
Como é possível perceber na Listagem 1, inicialmente devemos definir a versão plugin do SCD4J e as dependências do projeto. Notem que neste nosso exemplo existem apenas duas dependências: (1) o arquivo zip do Wildfly no site da JBoss e (2) um arquivo local que será utilizado como exemplo para testar o cluster nos diferentes ambientes. É importante ressaltar que, em casos reais, a resolução de dependências baseada em URL (arquivo zip do Wildfly no nosso exemplo) não é aconselhada uma vez que o provedor do artefato pode modificar o caminho ou mesmo a versão do arquivo. Se isto acontecer, o nosso pacote de instalação pode parar de funcionar inesperadamente. O ideal é que ambas estas dependências estejam no seu repositório de binários pré existente (como, por exemplo, no Artifactory ou no Nexus).
Listagem 2. Arquivo build.gradle - configuração do SCD4J
1. scd4j {
2. install {
3. modules "wildfly"
4. config project.hasProperty("envconfig") ? envconfig : ""
5. }
6. settings {
7. template {
8. engine "mustache"
9. }
10. }
11. }
Após a declaração do plugin e das dependências do projeto, precisamos ainda definir o que o SCD4J deve fazer quando executado. Como podemos ver na linha 3 da Listagem 2, ao executar o nosso projeto (gradlew.bat no Windows ou ./gradlew no Linux), o módulo wildfly será instalado. Além disto, também precisamos informar qual é o arquivo de configuração que deve ser utilizado. Como no nosso exemplo temos três ambientes diferentes (desenvolvimento, testes e produção) não podemos colocar um valor estático para a propriedade config (linha 4). Por este motivo, capturamos dinamicamente o valor setado em envconf e atribuímos este valor esta propriedade. Isto nos dá a liberdade de definir qual arquivo de configuração deve ser utilizado na hora do disparo da instalação.
Além das definições referentes ao que deve ser instalado, também podemos realizar outras configurações mais avançadas. Como por exemplo, podemos definir que optamos por utilizar o motor de templates mustache no lugar do padrão, que é Groovy Templates (linha 8 da mesma listagem).
Um arquivo de configuração para cada ambiente
Como mencionamos na seção anterior, a propriedade config da configuração do SCD4J deve conter o arquivo que gostaríamos de utilizar durante a instalação. Tal arquivo é, na verdade, um arquivo de propriedades onde as variáveis que requerem diferentes valores entre os ambientes são adicionadas. Por exemplo, o usuário e senha de um banco de dados devem ser diferentes entre os ambientes de desenvolvimento e produção para evitarmos incidentes. Sendo assim, para garantir a correta instalação nas diferentes máquinas, devemos ter, pelo menos, um arquivo .conf para cada ambiente.

Figura 3. Arquivos de configurações
Na Figura 3 podemos perceber que, para este exemplo, uma convenção de nomes foi criada com o intuito de facilmente identificar os ambientes e as portas HTTP nas quais os servidores serão instalados. Notem também que, em desenvolvimento, iremos instalar apenas uma instância do Wildfly. Já em testes e produção iremos instalar duas instâncias em cada máquina do cluster.
Listagem 3. Arquivo desenv-8080.conf
1. env=development
2. baseDir=/opt/scd4j-examples/WildflyClusterInstallation
3. portOffset=0
4. adminPassword=29a28757d330005880b98ead71ba2aa8
Para entender um pouco melhor como isto funciona, vamos analisar o arquivo desenv-8080.conf (Listagem 3). Na linha 1 estamos dizendo que o ambiente é de desenvolvimento (env é a única propriedade que é obrigatória e os possíveis valores são: development, testing, staging ou production). Já, na linha 2, definimos qual vai ser o diretório base onde a instalação deverá ocorrer. Na linha 3, o offset das portas do servidor e, por fim, na linha 4 a senha do console do Wildfly.
É válido ressaltar que, nos ambientes de homologação e produção é importante proteger informações sensíveis como, por exemplo, a senha que temos neste arquivo. Por motivos de escopo, não vamos cobrir estes detalhes, mas sugerimos fortemente que o leitor visite a documentação do SCD4J e leia a seção Encryption Tools. Além de não deixar aberta esta informação, o ato de criptografar uma propriedade também é uma medida de segurança. Uma vez que, quando existem propriedades criptografadas, apenas pessoas com a senha de descriptografia podem executar a instalação.
Entendendo as pré e pós condições
Em um projeto SCD4J, todos os módulos devem estar dentro do diretório modules. E, como podemos perceber na Figura 4, todos projetos possuem um arquivo gancho chamado Module.hook. Este arquivo é muito importante pois ele define o que deve ser executado antes e depois da instalação do módulo em si.
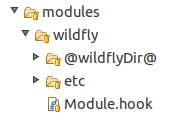
Figura 4. O módulo wildfly
Além do Module.hook, também precisamos colocar dentro do diretório do módulo todos os arquivos que devem ser instalados. Isto é, podemos ter arquivos para serem copiados, deletados ou mesmo templates para serem alterados em tempo de execução. Vamos começar visitando o arquivo Module.hook.
Listagem 4. Arquivo Module.hook - definições pre e post
1. ...
2. pre {
3. installOrStopWildfly()
4. installServerNode()
5. ...
6. }
7. post {
8. deployApp()
9. startWildfly()
10. }
11. ...
Na Listagem 4 temos as duas definições mais importantes deste arquivo. Dentro do escopo da definição pre{..} devemos programar o que deve ser realizado antes da cópia de arquivos do módulo iniciar. No nosso exemplo estamos chamando alguns métodos que serão explicados em seguida. Já, dentro da definição post{..} devemos programar o que deve ser realizado após a cópia de arquivos ser finalizada. Note que, uma vez que os hooks são escritos na linguagem Groovy, qualquer lógica programação desejada pode ser utilizada. Apenas como exemplo, vamos analisar alguns métodos implementados neste arquivo. Para mais detalhes, sugerimos ao leitor que estude o código-fonte encontrado no final deste artigo.
Listagem 5. Arquivo Module.hook - métodos auxiliares da definição pre
1. ...
2. void installOrStopWildfly(){
3. if(!exists(wildflyDir)) {
4. checkJava()
5. unzip('wildfly-8.2.0.Final.zip', baseDir)
6. } else {
7. log("Wildfly is already installed at $wildflyDir")
8. def st = status("wildfly-${httpPort}");
9. if(st.contains("running")) {
10. stop("wildfly-${httpPort}")
11. }
12. }
13. }
14.
15. void installServerNode() {
16. if(!exists(nodeDir)) {
17. cp("$wildflyDir/standalone", nodeDir)
18. }
19. }
20. ...
Antes de iniciar a instalação dos arquivos o SCD4J irá executar os métodos installOrStopWildfly() e installServerNode() (ver Listagem 4). O que o primeiro método faz (linhas 2-13 da Listagem 5) é, verificar se o servidor já está instalado e, caso negativo, descompacta a dependência do Wildfly (definida na Listagem 1) dentro do diretório escolhido. Caso o servidor já esteja instalado e esteja rodando, um sinal para parar o processo é então enviado. Note que, neste exemplo, diversos métodos utilitários (tais como: unzip, log, stop, cp, etc) são utilizados. Estes métodos são definidos na classe ModuleHook.java e, para mais detalhes e outras opções, sugerimos que a sua documentação JavaDoc seja analisada.
O segundo método (linhas 15-19 da Listagem 5) simplesmente verifica se o nodo do servidor já foi instalado anteriormente, caso negativo uma cópia do diretório standalone é realizada. Vale destacar que, por motivos de simplicidade e para garantir a maior similaridade possível entre os ambientes, não utilizamos, neste exemplo, o suporte de domain (cluster com gerência centralizada) oferecido pelo Wildfly. Contudo, apesar de algumas pessoas não saberem disto, é possível criar qualquer tipo de cluster utilizando apenas o suporte standalone do servidor.
Listagem 6. Arquivo Module.hook - métodos auxiliares da definição post
1. ...
2. void deployApp(){
3. cp("cluster-checker.war", "$nodeDir/deployments")
4. }
5.
6. void startWildfly(){
7. if(isLinux()) {
8. ...
9. start("wildfly-${httpPort}")
10. registryOnBoot("wildfly-${httpPort}")
11. }
12. }
13. ...
Já na Listagem 6, temos os métodos chamados na definição post{..} (ver Listagem 4), isto é, após a cópia de arquivos ser finalizada. O primeiro deles, linhas 2-4, simplesmente copia a dependência local da nossa aplicação (ver Listagem 1) para dentro do diretório deployments do nodo recém instalado (completando assim a implantação do sistema que iremos utilizar para testar o nosso cluster). Por fim, o segundo método, linhas 6-12, inicia e registra (no startup da máquina) o serviço do Wildfly apenas quando estamos rodando o instalador sobre o sistema operacional Linux. Se revisitarmos o nosso modelo definido na Figura 1, iremos perceber que apenas o ambiente do desenvolvedor roda em Windows e, como neste ambiente o serviço não deve subir automaticamente, optamos em realizar esta configuração apenas em testes e em produção.
Entendendo como funciona a cópia de arquivos
Após definido o que será executado antes e depois da instalação, precisamos definir ainda quais arquivos serão instalados/configurados durante a execução do SCD4J. Para isto, vamos analisar a Figura 5.
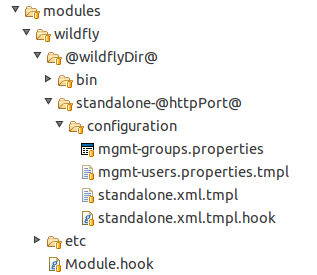
Figura 5. Detalhes do módulo Wildfly
Note que dentro do diretório do módulo Wildfly temos, além do nosso já conhecido Module.hook, diversos outros arquivos e diretórios. Estes arquivos e diretórios serão instalados no sistema operacional assim que a execução da definição pre{..} do Module.hook finalizar. Para que esta instalação ocorra corretamente é necessário que estes arquivos sejam colocados nos diretórios corretos. Isto é, o caminho do diretório dentro do módulo deve ser o mesmo que o arquivo terá no sistema operacional após finalizar a execução do SCD4J. Para definir estes caminhos existem duas possibilidades: (1) informar o caminho completo ou (2) utilizar uma variável que pode ser setada via programação (em arquivos .hook) ou estaticamente (em arquivos .conf). Neste nosso exemplo, decidimos utilizar variáveis (@wildflyDir@ e @httpPort@) uma vez que os diretórios de instalação podem variar entre as máquinas Windows e os servidores Linux.
As configurações mais simples são as dos arquivos que precisam ser apenas copiados para o diretório de destino. Neste caso, basta colocar o arquivo no diretório correto dentro do instalador (ex. mgmt-groups.properties na Figura 5). Porém, existem casos que é só possível saber o que deve ser configurado em tempo de execução, nestes casos devemos adicionar a extensão .tmpl ao final do arquivo (ex. mgmt-users.properties.tmpl e standalone.xml.tmpl). O que o SCD4J faz ao verificar que um arquivo termina com .tmpl é resolver o template utilizando a engine configurada previamente (Listagem 2). Somente após esta resolução o arquivo é copiado para o seu destino final.
Listagem 7. Trecho do arquivo standalone.xml.tmpl
1. 1. ...
2. </subsystem>
3. {{^isDevelopment}}
4. <subsystem xmlns="urn:jboss:domain:modcluster:1.2">
5. ...
6. </subsystem>
7. {{/isDevelopment}}
8. <subsystem xmlns="urn:jboss:domain:naming:2.0">
9. ...
Apenas para elucidar a utilização de templates, temos o exemplo da Listagem 7. Como podemos perceber, em arquivos .tmpl, devemos sempre utilizar a linguagem do motor de templates definida no arquivo build.gradle; no nosso caso, mustache. Por exemplo, nesta mesma listagem, estamos dizendo que não queremos instalar a definição do subsystem de modcluster do Wildfly nas máquinas de desenvolvimento (linhas 3-7), uma vez que o desenvolvedor não precisa de um balanceador de carga para realizar as suas atividades diárias de programação.
Por fim, ainda existem situações em que precisamos adicionar ganchos (hooks) de pré e pós condições nas instalações dos arquivos. Por exemplo, veja standalone.xml.tmpl.hook na Figura 5. Este arquivo, nada mais é do que um gancho de pré e pós condição para o arquivo standalone.xml.tmpl. Isto é, dentro dele temos as mesmas definições pre{..} e post{..} que possuímos no Module.hook. A principal diferença que temos entre o hook de módulo e os hooks de arquivos é que na implementação do primeiro devemos utilizar os métodos auxiliares definidos na classe ModuleHook.java, enquanto, no segundo, os métodos auxiliares são definidos na classe FileHook.java.
Executando a instalação
Para executar o nosso projeto, primeiramente precisamos saber em qual ambiente o instalador está sendo rodado. Esta informação, apesar de parecer ingênua, é muito importante pois é necessário informar no comando o nome do arquivo de configuração correto. Com isto bem claro, basta digitar: ./gradlew -Penvconfig=wildfly/NOME_ARQUIVO.conf na linha de comando.
Box 3. Trava de segurança
É importante mencionar que o SCD4J possui uma trava de segurança que evita que, por exemplo, um arquivo de configuração de testes rode em ambientes de produção. Para saber mais como utilizar esta trava, visite a documentação da ferramenta na seção Packaging and Distributing, subseção Defining Environments.
Apenas como um exemplo, iremos enumerar os passos para rodar o nosso projeto em uma máquina Linux simulando a instalação de um ambiente de testes:
- Inicialmente devemos estar logado com o usuário root no sistema operacional;
- Em seguida, precisamos baixar o código-fonte do exemplo (ver link no final deste artigo);
- Com o código-fonte salvo em um diretório qualquer, iremos instalar o primeiro nodo do cluster digitando o seguinte comando na raiz do projeto (diretório onde se encontra o arquivo build.gradle): ./gradlew -Penvconfig=wildfly/testing-8180.conf
- Ao terminar a instalação do primeiro nodo partirmos para o segundo executando o comando: ./gradlew -Penvconfig=wildfly/testing-8181.conf
- Neste momento já possuímos ambos os nodos do cluster completamente configurados e prontos para receber requisições. Nos resta então verificar se tudo aconteceu como o esperado. Para tal, precisamos abrir o navegador e acessar o sistema instalado no primeiro nodo do nosso cluster: http://localhost:8180/cluster-checker
- Ao pressionar a tecla F5 algumas vezes iremos perceber que a contagem do número de requisições irá aumentar respectivamente (Figura 6).

Figura 6. Acessado a instância 8180
- Uma vez que está tudo certo com a instalação do primeiro nodo, podemos verificar o segundo abrindo uma outra aba navegador e digitando: http://localhost:8181/cluster-checker.

Figura 7. Acessado a instância 8181
Neste momento, se nenhum erro ocorreu durante a instalação, iremos perceber que o número de requisições continua de onde a primeira instância parou (Figura 7). Isto comprova que a replicação de sessão web está funcionando corretamente e, portanto, que o nosso cluster está no ar rodando sem problema algum.
Considerações finais
Como foi mencionado no inicio deste artigo, a automatização de ambientes está deixando de ser um diferencial entre as empresas para se tornar um padrão dentro do mundo de desenvolvimento de software. Infelizmente, as ferramentas mais conhecidas são muito complexas e exigem uma curva de aprendizado muito maior do que as pequenas e médias empresas querem pagar. Com este intuito, surgiu uma ferramenta chamada SCD4J que visa de cobrir este gap carente em automatização no mundo Java.
No decorrer deste artigo, discutimos como realizar a instalação de um cluster de Wildfly utilizando tal ferramenta. Porém, é importante ressaltar que esta instalação é apenas um exemplo do que pode ser feito automaticamente. Além disto, não podemos esquecer que as empresas devem focar no objetivo final, que é a instalação completa dos ambientes diretamente amarrada os seu processo de entrega contínua. Isto é, a cada build realizado os ambientes devem ser re-instalados. Esta estratégia garante que não apenas o sistema seja testado inúmeras vezes mas, também, a instalação do mesmo. Esta solução, além de trazer tranquilidade e confiança para todos os integrantes do desenvolvimento, também evita surpresas na hora do going live.
Links
Documentação do SCD4J
Código-fonte utilizado como exemplo neste artigo
Livro sobre Contínuos Delivery do Jez Humble
Servidor de Aplicação Wildfly
Motor de templates mustache
Puppet
Chef
Fernando Rubbo possui cerca de 14 anos de experiência em desenvolvimento de software. Atualmente trabalha como Ads Solution Engineer no Google e é mestre em Engenharia de Software pela Universidade Federal do Rio Grande do Sul (UFRGS). Fernando já vivenciou praticamente todas as áreas do ciclo do desenvolvimento de software atuando principalmente como consultor, líder técnico, arquiteto de software e, também, professor universitário.
Nenhum comentário:
Postar um comentário